
A DataFrame is the primary data structure of the Pandas library in Python and is commonly used for storing and working with tabular data.
A common operation that could be performed on such data is to create the DataFrame by appending one row at a time to work with the information in a better manner.
To start working with Pandas, we first need to import it:
import pandas as pd
Let us understand this operation with the help of an example. Consider the following DataFrame containing 3 students with names A, B, and C and their corresponding marks (out of 10) for two subjects, Mathematics and Physics.
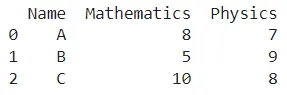
Code snippet for generating the above DataFrame:
import pandas as pd
# Dictionary for our data
data = {'Name' : ['A', 'B', 'C'], 'Mathematics' : [8, 5, 10], 'Physics' : [7, 9, 8]}
# DataFrame for the dictionary
df = pd.DataFrame(data)
# Printing the DataFrame
print(df)
Here, data is a dictionary we created to initialize the DataFrame. For this, we use the DataFrame() function of the Pandas library which takes the dictionary as an argument and returns the required DataFrame.
Now, let’s say we need to create this dataframe by appending one row at a time instead of using a dictionary to do so. The resulting output would be the same as before and look like this :
Let us look at different ways of performing this operation on a given DataFrame :
In this method, we use the append() function to create a dataframe by appending data in a row-by-row fashion.
First, we create an empty dataframe with the column labels and then use a for loop to add the data row by row.
We pass the data for a row as a parameter to the append() function. We use square brackets to access the data items inside the dictionary, for example, data[‘Name’][0] is used to access the first element inside the list corresponding to the name column.
Inside the append function, we also need to pass the parameter ignore_index as True. The updates are not made in place so reassignment is required.
Let us take a look at the corresponding code snippet and generated output for this method :
# Importing pandas
import pandas as pd
# Dictionary for our data
data = {'Name' : ['A', 'B', 'C'], 'Mathematics' : [8, 5, 10], 'Physics' : [7, 9, 8]}
# Creating an empty dataframe
df = pd.DataFrame(columns = ['Name', 'Mathematics', 'Physics'])
# Appending row wise
for i in range(3):
  df = df.append({'Name' : data['Name'][i], 'Mathematics' : data['Mathematics'][i], 'Physics' : data['Physics'][i]}, ignore_index = True)
# PrintingÂ
print(df)
Output :
In this method, we use the loc property to access a row of the dataframe corresponding to the index that is passed as a parameter to this.
To specify the contents of a row, we use a list containing the required data elements. We use square brackets to access the data items inside the dictionary, for example, data[‘Name’][0] is used to access the first element inside the list corresponding to the name column.
Let us take a look at the corresponding code snippet and generated output for this method:
# Importing pandas
import pandas as pd
# Dictionary for our data
data = {'Name' : ['A', 'B', 'C'], 'Mathematics' : [8, 5, 10], 'Physics' : [7, 9, 8]}
# Creating an empty dataframe
df = pd.DataFrame(columns = ['Name', 'Mathematics', 'Physics'])
# Appending row wise
for i in range(3):
  df.loc[i] = [data['Name'][i], data['Mathematics'][i], data['Physics'][i]]
# PrintingÂ
print(df)
Output :
In this topic, we have learned to create a Pandas DataFrame by appending one row at a time, following a running example of test scores of students in different subjects, thus giving us an intuition of how this concept could be applied in real-world situations. Feel free to reach out to info.javaexercise@gmail.com in case of any suggestions.